
文摘
以前的语料库研究表明,英语拼写系统(伯格和Aronoff morpho-graphic2017年)黏贴拼在一个一致的方式(例如,喜爱诸多;著名的)它们有别于同音的字结尾没有语法功能(例如,喜爱我们;奖金)。本文调查如果英语拼写能力的应用这些规律隐式小说的拼写单词,这些规律的应用程序是否与英语写作系统调制通过经验。
参与者与不同程度的专业知识在英语写作系统被要求拼写/əs /小说结尾的单词,它提出了口头的形容词上下文(即。,偏压对词缀拼写喜爱我们的;)或一个名词(即上下文。偏压对另一种拼写,如喜爱美国;)。结果表明,引起更多的形容词上下文喜爱我们的;拼写比名词上下文,表明参与者morpho-graphic拼写规律应用于小说话语标记适当的词汇范畴。此外,有一个调制的拼写能力:较高的参与者的专业知识在英语拼写系统,更新奇话他们拼写根据morpho-graphic拼写规律。
总之,英语拼写能力意识到morpho-graphic拼写规律没有明确的指导和应用这些新单词。他们逐渐诱导规律从输入,结果在应用程序更健壮的规则增加了英语写作系统的经验和专业知识。
英语拼写系统是出了名的难以获得的声誉,甚至“混乱”,是著名的以杰拉德Nolst Trenite(1922)在他的诗歌“混乱”,他对比词拼写相似但明显不同(例如,虽然vs。通过vs。咳嗽,以字母顺序喜爱咳嗽;明显/əʊ/,/ u: / /ɒf /分别),脚注1反映英语拼写的不透明的自然系统(相对于其他更透明的如意大利)。
这种不透明性对grapheme-to-phoneme以及phoneme-to-grapheme通讯可能影响不同的字母和音素在不同程度。例如,元音尤其影响——在两个方向上:首先,这封信喜爱;是明显不同的命运,帕特和洗(即。,一个年代/eɪ/, /æ/ and /ɒ/ respectively) and, second, the diphthong /aɪ/ is represented by different letters in the words我的,派,我的(即。,‹i›, ‹ie› and ‹y› respectively; cf. (Gontijo et al.2003年))。Gontijo et al。(2003年)量化grapheme-phoneme通讯,使用CELEX语料库(Baayen et al。1995年)来识别可能在英式英语发音的字母建立正字法深度的测量。关于字母;喜爱,例如,他们发现大约50%的出现明显/æ/,而剩下的50%有一个进一步的8种不同的发音,因此被明显比辅音不定地,其中大部分有一个或两个发音变异。
至关重要的是,字母不应被视为孤立的字母或字母序列的选择受制于相邻音素和字母。凯斯勒和Treiman (2001年)表明,英语单音节的(和形态学单纯形)话说,音节拼写的核严重依赖它的尾声。例如,对上面的字母;喜爱,发音/æ/是默认,而空尾声或与喜爱r尾声;导致发音与喜爱l /ɑ/和强音;发音/ɔ/,在别人。
除了字母和音素,有更大的单位,会影响用英语拼写。例如,拼写可能反映一个词的词源(例如,喜爱b;保存这封信怀疑,它发源于拉丁语动词dubitare“犹豫”)或形态的关系(例如,派生的名词健康保留《ea;从其基地治愈尽管发音变化)。关于后者,除了根效果的一致性治愈- - - - - -健康示例(伊和安德森1984年),屈折词缀拼在一个一致的方法,不同于同音异义的序列没有语法功能(例如,卡尼1994年)。例如,word-final / z /字母所代表的喜爱等复数名词;(眼睛)眉毛和bries,而其他字母序列,如喜爱se;而喜爱泽;用于形态学单纯形,如浏览和微风与变形,同音异义的例子(词缀系统语料库分析-年代和- - - - - -艾德,看到冰山等。2014年)。
同样,伯格和Aronoff (2017年显示同样的拼写一致性四个派生后缀。例如,拼写喜爱我们的;word-final序列/əs /只是用于形容词(例如,著名的,欢乐的),而相同的最终序列是由其他字母词汇类别(例如,美国;喜爱,喜爱;或喜爱冰;名词奖金,网球和办公室分别)。因此,拼写系统可以比口头语言更丰富,可以让读者利用这额外的信息在语言处理(例如,通过减少歧义和宽松词汇范畴的任务)。至关重要的是,然而,这些规律在黏贴的拼写,或者Aronoff et al。(2016年)项“morpho-graphic拼写”——通过说明性的压力,但并没有实现,根据伯格和Aronoff (2017年),开发自然的自我组织过程和通常不教明确的读者。因此,如果读者意识到这些morpho-graphic拼写规律,他们必须从输入通过诱导他们曝光。
当谈到拼写(即。,the ‘translation’ of spoken language into written format), there are generally two routes through which this could be achieved: Firstly, via accessing the lexical entry with information about a word’s orthographic representation and, secondly, via phoneme-grapheme correspondences, which may be more or less transparent depending on the language in question. These two routes have been shown to interact for the spelling of existing words. For instance, Delattre et al. (2006年)报告快单词拼写时间与低概率高概率phoneme-to-grapheme通讯相比,表明sublexical路线(即。通过phoneme-grapheme通讯)必须访问这里。
更有趣的测试用例的自然sublexical路线是非言词的拼写,词汇的路线不适用,因为不能为这些小说词汇条目。巴里和西摩(1988年),例如,表明参与者倾向于包含音素/我:法术非言词与喜爱/ ea;或者包含/ u: /喜爱oo;,这两种是最常见的拼写各自的声音。如上所述,grapheme-phoneme通讯的可靠性可能不同单个序列(例如,使用《ea;拼写相似程度作为拼写第二多喜爱ee;(40比39%),而频率差异更明显喜爱oo;与喜爱电子战;以48比10%)。
因此,应该考虑更多的上下文。更具体地说,对于word-final序列,形态信息,正如上面指出的,相关的,导致morpho-graphic拼写等喜爱ed;过去时态和喜爱我们的形容词;对比选择,non-morphological拼写等喜爱t;或者喜爱d;我们喜爱;或喜爱;分别。已经有一些研究调查开发读者/拼写是否知道英语拼写系统隐含的规律时屈折词缀。的拼写word-final / d /和/ t / Nunes et al。(1997 b观察到6-to-9-year-old孩子拼两个过去时态动词(例如,被称为,睡)和nonverbs(例如,鸟,软)语音学上发现拼写喜爱ed;之前,他们最初不仅用于普通动词,但也不正确,不规则动词(例如,sleped为睡)和nonverbs(例如,sof为软)。经过一个中间阶段overregularisations是局限于动词(即。,regular and irregular forms), the children finally reached the target-like distribution of ‹ed›. Importantly, in a study with novel verbs and nonverbs, Nunes et al. (1997年,一个)发现了相同的模式,排除混淆由于知识的个人物品和背诵他们的拼写。
然而,总有几个因素需要考虑的决定为一个特定的拼写。例如,有额外的限制对字母可能会或可能不会出现在一起,语法语境需要正确分析来决定哪种类型的词(例如词汇范畴,单数和复数,紧张的)一个是面对。关于前者,坎普和科比(2003年),看的拼写word-final / z /在现实和小说在复数词与non-plural上下文,包括phonotactic约束在他们的设计:虽然这封信喜爱z;从未出现后表示英语辅音(例如,*喜爱;bz报道),有不同的拼写音素/ z /长元音后(例如,喜爱年代;跳蚤喜爱se;请喜爱泽;微风)。坎普和科比发现儿童和成人都更准确的使用《年代;拼写为复数形态上下文和语音约束对齐。例如,参与者consonant-final小说的大部分单词拼写如/照明灯具:新西兰/喜爱pleens;复数的上下文(即。,when the ‹z› spelling was discouraged both by sentence context and the statistical information that ‹z› does not appear after voiced consonants), while vowel-final novel words such as /pri:z/ elicited fewer ‹s› spellings and more alternative such as ‹preeze› or ‹prease›. Interestingly, children who were good spellers in general and those adults with university education (i.e., current students, who were exposed to large amounts of reading and writing on a daily basis) were better at using the morphological information in the more difficult context of long vowels, suggesting that there are individual differences with respect to the use of specific types of information.
重要的是,拼写规律变形(尤其是复数和过去时态的形成)非常常规的和透明的,全面应用,这就是为什么这些规则常常在教室里教明确。因此,重要的是要看更多的隐含规则,不太可能得到解决拼写收购过程中明确:Morpho-graphic拼写派生后缀的成年人完全收购了英语拼写系统。这就是Ulicheva et al。(2020年),测试是否熟练的读者利用morpho-graphic拼写规律诱导小说语言的语法范畴,在理解和生产。在一个分类任务中,他们显示,参与者更有可能对小说进行分类与诊断的形容词的后缀(例如,-能力,我们公司和- - - - - -少在gufable,raxous和jevless),而小说与名义后缀(例如,-表示“状态”,一个和- - - - - -呃在vixment,dofan和障碍物),而标记为代表的名词,这表明熟练的读者对小说的理解单词的协助下形态学信息编码在黏贴高度可靠的拼写。
在拼写的生产任务,Ulicheva等人还发现,熟练的读者利用句子的上下文提供的词汇范畴信息拼最后的小说文字序列按照morpho-graphic拼写规律。例如,参与者更容易拼最后序列/əs词缀拼写喜爱这部小说诸多;词/ wɪvəs /(1),它出现在一个形容词上下文,比/ɪptəs /名词上下文(2)。
- (1)
早上的空气闻起来/ wɪvəs /当他们走过农村。
- (2)
飞行员警告说,重大/ɪptəs /很可能在着陆。
(Ulicheva et al。2020年附录C)
重要的是,Ulicheva等人发现的影响(包括分类和拼写任务)强有力的词缀高度可靠拼写(即。,that only occurred for the word class marked by the derivational affix and not another), suggesting that skilled readers acquired “knowledge [about] the statistical structure of the writing system […] [through] implicit statistical learning processes” (p. 13).
然而,上面的研究报道天花板效应(即。,完美的应用隐式规则)。更具体地说,甚至在高度可靠的情况下拼写等喜爱我们的形容词结束;/əs /(名词和替代拼写),Ulicheva et al。’s参与者只产生29%的病例的词缀拼写形容词上下文(Ulicheva、个人通信),如果统计信息得到全面实施,期望一个close-to-ceiling喜爱我们的生产;拼写。同样,复数喜爱的生产年代;拼写在坎普和科比的(2003年)元音上下文不超过64%,这表明这两个统计grapheme-phoneme上下文和语法信息交互。
至关重要的是,在这两个新的单词拼写的研究中,两种类型的信息交互:知识的统计特征grapheme-phoneme通讯和识别相关的语法信息的上下文。更具体地说,新单词拼写揭示参与者的知识拼写系统为目的,参与者必须完成三个步骤:首先,他们必须确定目标音素在输入(例如,/əs /或/ z /)。其次,他们必须利用上下文来确定哪些字类(例如,/əs /形容词,名词/ z /)和文字形式(例如,单数和复数)是必需的。最后,他们必须映射音素字母,重量(即不同类型的信息。,general correspondences and specific rules depending on the sentence context or neighbouring phonemes). Only when all of the above steps have been completed, can we expect knowledge of implicit spelling regularities to be evident.
从这之后,本研究旨在调查morpho-graphic拼写的数量是否可以增加实验操作,使参与者更容易识别和利用语法上下文信息。因此,当下小说单词拼写研究了以下四个修改而Ulicheva et al。' s设计:(1)使用简单的可预测的句子上下文,以避免潜在的语义加工其他材料的影响实验的句子,使小说类词非常可预测的。(2)而不是口头只有小说词(即。,在isolation, with the context sentence presented visually on the screen), participants listened to the novel word within the sentence context to increase the integration of the novel word into the context. (3) In order to avoid confounds due to idiosyncrasies of individual novel words (e.g., associations with existing words due to phonological similarities), each novel word was presented in both a context that was predicted to elicit the affix spelling and one that was not (using a Latin Square design). (4) In order to increase power, only one affix was investigated, namely -我们公司。这个词缀被选中,因为它是高度表明adjectivehood(见伯格和Aronoff2017年),产生了最清晰的区分一致(ADJ)和不一致(N)上下文Ulicheva et al。2020年)。
此外,本研究调查的影响个体差异的应用morpho-graphic拼写规律,跟进坎普和科比的(2003年)观察到更好的拼写者更有可能利用形态学信息。作为一个测量的专业知识与英语拼写系统,一般的拼写测量包括在统计分析。作为诱导morpho-graphic拼写规律从输入可能取决于输入一个拼字的人收到的数量,目前的研究包括参与者较少体验英语写作系统(即。他们有更少的时间做统计推断英语拼写系统)。这些都是高级英语学习者,形成一个团体,是谁与测试成人英语拼写能力对其他变量如教育背景(较低的替代的母语为英语的成年人相比,学术成就)和认知能力(另类的孩子相比)。
上述修改的Ulicheva et al . (2020年)设计,我们的目标是让这个词类别信息的关键morpho-graphic拼写规律的应用更方便的参与者,谁将使用更多morpho-graphic喜爱诸多;拼写适当的形容词上下文(相对于一个名词上下文)。然而,就在所有的可能性,也是替代拼写。预测哪些替代拼写(例如,美国;喜爱,喜爱;)将选择通常是很难实现完全基于简单phoneme-grapheme通讯因为感兴趣的元音(即。,/ə/)是一个元音,这可能是由几乎所有元音字母在非重读音节。然而,随着伯格和Aronoff (2017年,45页)语料库分析显示喜爱我们;最常见的拼写最后序列进行调查(类型)的18%后morpho-graphic喜爱我们的;(类型)的52%,这是预计将发生的拼写最如果morpho-graphic拼写没有应用。
此外,当涉及到集成不同类型的信息(即。,context and morpho-graphic regularities), we expect better spellers to be at an advantage because, with spelling regularities firmly rooted, they have more resources left for the integration of different types of information. If awareness of morpho-graphic spelling regularities depends on the amount of experience with the writing system, less experienced and ‘poorer’ spellers might show a lower percentage of morpho-graphic spellings.
材料
实验项目,二十庸俗的非言词与正字法CVCC CCVC或CVVC脚注3与一个额外的结构,可以明显最后/əs /序列是英语词汇的从数据库中选择项目(Balota et al。2007年)。虽然non-morphological拼写喜爱我们的书面形式;所有包含6个字母(例如,喜爱cradus;,喜爱lazzus;),五之间的语音形式由不同(例如,/ læzəs /)和6(例如,/ krædəs /)音素。建立了使用ClearPOND数据库(Marian et al。2012年),大部分的实验项目没有任何语音邻居,除了喜爱purnus;(1邻居:喜爱目的;)和喜爱vushus;(2)邻居:喜爱甜美的;,喜爱恶性;)。实验项目的完整列表,请参阅表A1在附录中。
每个新单词在短的描述,提出了一个角色,他的名字成立的介绍性的句子(50%为男性,50%是女性)。第二个句子的句法环境的描述然后确定了新颖的词作为一个形容词(见(3))或作为一个名词(见(3 b))来测试是否小说词的语法分类信息用于决策的喜爱我们的;拼写与另一个拼写(例如,喜爱美国;)。(即句子上下文保持简单。,一个ll sentences used “is very” and “is a” respectively) in order to decrease possible semantic interference from other material in the sentence and allow participants to make maximal use of the word class information of the novel word provided by these contexts.
- (3)
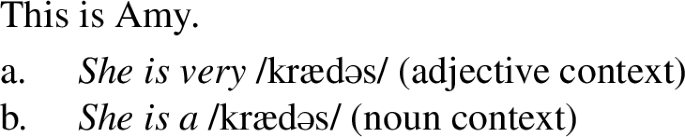

如果参与者意识到隐式morpho-graphic拼写规律,他们预计将产生更多的喜爱我们的;拼写,指示形容词的地位,在上下文的小说词是形容词与名词的上下文。
此外,四十five-to-seven-letter的话选为填充物。三十的结束四个常见的拼写序列与潜在的辅音翻倍(即。,‹id›, ‹it›, ‹le›, ‹ow›), in order to draw attention away from the repeated /əs/ sequence in the experimental items. The remaining ten items contained the vowel /i:/, a notoriously difficult sound for spellers as there are a multitude of different spellings for it (e.g., ‹e›, ‹ea›, ‹ee›, ‹ei›, ‹ie›, etc.). Half of the fillers appeared in a verb context (following the modal verb可以),另一半在形容词或名词上下文,因此确保每个上下文出现在三分之一的60试验。
刺激记录由男性美式英语的本地人,他并没有意识到研究的目的。拼写的母语有列表形式的小说的话,拼写与实验项目与喜爱美国;为了避免任何潜在的偏见的发音对词缀的拼写。这部小说的话记录在隔离,与实验和填充物品混合,防止刺激模式的检测,和后来拼接到句子上下文使用软件无畏(2.1.3版本,无畏的团队2017年)。这种方式,上下文的句子是相同的跨项目和小说关键字相同的的两个条件。
过程
参与者被单独的测试在一个安静的房间。为小说单词拼写的任务,他们坐在前面的两个笔记本电脑15”屏幕。一台计算机的听觉刺激,参与者通过耳机听,并显示上下文句子在白色背景上的黑色写作(字体大小:28)控制的DMDX软件(福斯特和福斯特2003年)。第二个句子是重复经过短暂的停顿,使参与者听小说第二次。在其他电脑上,参与者类型小说词变成一个简单的文本编辑计划提供的试验数量,用拼写检查软件禁用。参与者被要求评估他们的拼写为了避免拼写错误并继续下一个试验时准备这样做。任务持续了大约20分钟。
除了主要的实验中,两个额外的措施:
拼写的能力测量是基于30个词取自伯特和泰特(2002年Exp。(3)) 95低频物品。项被选中(i)提供一系列困难,基于波特的准确性分数和泰特的参与者和(2)是可能的一部分大学生词汇(包括本地和非本地)。在附录中提供的单词列表。小说的设置是一样的单词拼写的任务,有一个笔记本电脑用于刺激表示,另一个用于打字。参与者首先听取了目标词在隔离,消除歧义,在一个句子上下文(来自在线牛津英语词典),记录下男性的美式英语母语也记录了实验刺激;然后输入目标词在文本编辑计划第二计算机在继续下一个单词之前。参与者被要求检查他们的答案,以避免输入错误。
此外,实验中,参与者完成一个简短的标准化词汇决定LexTALE脚注4(Lemhofer和布罗尔斯玛2012年),用英语来衡量他们的词汇量大小和显示一般英语水平。这也是实现DMDX和参与者表示按钮按下手柄上的字母的字符串是否呈现在电脑屏幕上是现有的英文单词或不是。目标是在白写在黑色背景和呆在屏幕上,直到参与者按下一个按钮。这个任务花了约5分钟。
结果
参与者的特征
如上所述,两项措施的参与者的语言技能是:拼写能力和词汇量大小与LexTALE测量任务。首先,拼写能力的措施,正确拼写的百分比计算。形态学相关版本的目标词(例如,复数:先行词而不是先行词;派生的形式:复发性而不是递归式,依从性而不是附着)也被认为是正确的反应。参与者的拼写能力和总结其他参与者特征(即单独提供的经验。,英语母语者)和(即拼写没有经验。学生的英语)在表1,包括组差异的显著性检验。意味着我们可以看到,有经验的和没有经验的拼字组明显不同,与经验丰富的组有更高的平均评分。然而,两组分数显示广泛的拼写能力,覆盖同样广泛。拼写虽然有更多经验的低端,26拼写没有经验的学生达到50%或更多的分数,显示一个类似的蔓延范围为32拼写有经验的学生。
第二,关于LexTALE分数,一个类似的情况出现的两组:而经验丰富的拼写能力明显高于LexTALE成绩比没有经验的人,每组有个人得分低或高的规模、覆盖广泛。为了捕获这个词汇量大小的分布在两组,LexTALE分数作为连续变量的模型,而不是人为地将参与者分成组根据他们的语言背景。脚注5
新单词拼写
之前分析,三种类型的数据点被移除:(1)缺失的数据(N = 1),(2)产品现有的词可能是意外(例如,/ vʌʃəs /拼喜爱灌木;,可能与词的元音喜爱总线;而不是音素/ʊ)或听起来类似于小说的话在某种程度上(例如,喜爱懒散;/ leɪzəs / / læzəs / N = 33),和(3)产品以字母开始喜爱;,表明参与者解释这篇文章一个名词的条件作为小说的一部分词,本质上导致这个上下文句子作为一个形容词上下文的影响试验(N = 14)。这导致2.5%的数据。
参与者的作品进行分析对字母是用来拼最后/əs /序列的关键项目。我们可以看到在桌子上2,列出了所有拼写,出现的次数至少10倍,最常见的拼写是美国;喜爱,喜爱我们的;喜爱;,占所有拼写的大约三分之二。此外,表也显示了分布在两个不同的环境中,与所有上市拼写在上下文中使用。对拼写的兴趣,而参与者小说单词拼写与喜爱我们的;或其语素变体喜爱欠条;或喜爱eous;脚注6在这两个形容词(273 941 = 29%小说的话语;看到高亮在表2)和名词上下文(146 931年的小说《话说= 16%),参与者的可能性选择喜爱的诸多;拼写是两个,一个形容词与名词上下文(即。419年,65%的喜爱我们的;拼写出现在形容词上下文)。
为了测试是否拼写感兴趣的观察到的差异,即喜爱我们的;,在两个上下文数据可靠,数据分析普遍线性mixed-effects模型(GLMM)个带有罗吉连接函数,使用lme4包(版本1.1 -19年,贝茨等。2015年3.4.1)R(版本,R核心团队2017年)。因变量(DV)最后的声音序列是否拼写与喜爱我们的;(1:喜爱我们的;,脚注70:其他拼写)。感兴趣的固定效应是上下文(形容词与名词;sum-coded)。此外,集中因素试验数量,拼写能力,LexTALE得分,收购时代(AoA)和年龄作为固定效应控制潜在的学习或疲劳效应和个体差异。为了测试基于拼写能力的个体差异(如先前的研究的建议)以及控制的潜在影响收购的后时代(AoA)的英语实验操纵,这是测试,如果包含交互的拼写能力的因素,分别LexTALE分数和AoA与上下文是合理的。只有拼写能力显著提高模型之间的交互,因此包括在内。建立了固定效应后,包含随机试验数量和上下文的斜坡上进行了测试,导致一个随机边坡结构与试验数量by-participant随机的斜率。
与原始模型不收敛由于完全分离脚注8在数据(例如,参与者有从未使用过一个喜爱诸多;拼写这个形容词上下文和人总是做),一个弱信息引入固定效应参数之前,使用blme包(1.0版本4,钟等。2013年)r .这样一个之前仍然允许检测大效果,同时减少的概率非常大的差异,会导致模型收敛的问题。前对所有固定效应是正态分布的均值0和3的标准差;这意味着95%的先验分布log-odds−6和6之间,这仍然是一个巨大的影响。
的输出提供了统计分析表3。有主要影响的上下文(p<措施),反映出这一事实参与者产生更多喜爱我们的形容词;拼写(米= 29.01%)相比,名词上下文(米= 15.68%)。与拼写能力,至关重要的是,有一个互动脚注9表明“更好”的拼写能力的影响通过上下文操纵程度高于“贫穷”拼写能力。图1看到这种交互喜爱我们的策划之间的差异百分比;拼写的形容词和名词为每个参与者在上下文y设在反对他们的拼写能力分数x设在。拼写能力得分越高,越有可能被参与者与喜爱我们的魔法小说在这个形容词词上下文;而不这样做名词上下文(或者至少只有一个较低的程度上)。脚注10

每个参与者的喜爱我们的生产;拼写的形容词与名词上下文(比例的喜爱诸多;拼写形容词上下文-比例的喜爱诸多;拼写名词上下文)策划对拼写能力得分
另外,有试验数量的影响(p= .029)和AoA (p= .015),积极的估计表明(a)参与者更容易产生喜爱我们的;拼写在实验和(b)参与者接触到英语以后更多的单词拼写与喜爱我们的;整体比早接触英语。
讨论
目前的研究发现,参与者更容易拼写小说/əs /单词的词缀拼写喜爱我们;当它出现在一个合适的形容词比当它出现在名词的上下文语境,这表明参与者意识到隐式morpho-graphic规律的英语拼写系统。拼写喜爱我们的;因此表明adjectivehood小说的话,不太可能用在一个不适当的名词上下文。
然而,尽管修改设计(而Ulicheva et al。(2020年)设置)语法环境更加透明、可预测,针对增加的应用morpho-graphic拼写,喜爱我们的百分比;拼写还相当低。如果隐式规则分配形容词地位喜爱我们的;拼写在现有的词(管理镜像发生了伯格和Aronoff (2017年)语料库分析),它应该被用于形容词百分比高于实际29%上下文,它不应该发生在名词上下文(它是用11%的时间)。这种模式的喜爱我们的;发生复制Ulicheva et al。(2020年)相对较低比例的喜爱我们的;使用(29%)。所以,尽管本研究的参与者听过这部小说词嵌在听力中(而不是只听到这部小说在孤立词)除了看到屏幕上的上下文句子,参与者可能仍然忽略了上下文句子,等待着新颖的词代替。在最近的一项研究中,Treiman et al。(2020年)实现的另一种方法使参与者积极参与上下文句子:参与者写下句子上下文包括小说的话。然而,Treiman et al的参与者与喜爱我们的拼写单词;甚至更少,只有12%的喜爱诸多;拼写形容词上下文。
然而,参与者在当前研究显示语法语境意识——也对其他形态产生的拼写。更具体地说,一个类似小说的代表词的语法分类可以观察到喜爱少;喜爱ess;。而形容词的词缀拼写喜爱少;(如无害的)主要出现在形容词上下文(20 29出现),名义上拼写喜爱ess;(指女性人类或动物等女主人或母狮)显示了相反的模式,73%的出现(54 74)的名词上下文。
另外,关于词缀拼写喜爱ess;,不仅仅是词汇范畴信息可能影响拼写选择:拼写喜爱ess;,这可能代表了名义上的词缀ess,更有可能被用于上下文句子女性主题(例如,她句子中主语:44 54名词出现的上下文),表明参与者的选择可能是受后缀的语义信息——的影响ess,指的是女性而不是男性。
可能的替代拼写,《我们》;变体是迄今为止最常用,甚至比morpho-graphic更多喜爱我们的;拼写,一种高频率的现有英语词汇(cf。伯格和Aronoff2017年)。这是基于伯格和Aronoff语料库的分析预测,发现喜爱我们;拼写是最常见的选择。
喜爱我们的高比率;而喜爱我们的;拼写可能是由于参与者的不愿让这部小说文字看起来像形态复杂的单词。如果这封信序列喜爱我们的;被视为一个词缀,参与者可能会认为这部小说文字来自基本熟悉。小说中文字在目前的研究中,这个基础不可能被确认。为了进一步研究这种可能性,未来的研究可以与设计,介绍了基地和复杂的形式。
相比之下,参与者也可以采用类比策略由于在小说单词拼写词汇路线的影响。参与者可能会在心理词典搜索条目匹配输入字符串最密切和应用相同的拼写。作为目前研究没有系统地操纵小说“相似性现有的话说,目前的数据不能给一个明确的答复这个选项。然而,当看着两个实验项目,有一个或两个音位邻居,类比的潜在影响可能是可见的,这个词喜爱vushus;确实产生了大量的喜爱欠条;拼写邻国甜美的和恶性不考虑上下文(名词形容词上下文:17日上下文:15日其他拼写:8或更少的出现)。不过,对于喜爱purnus;没有类似的拼写与喜爱ose;在其邻国目的。
比言语类比也可以运行在更小的单位。凯斯勒和Treiman (2001年)显示,元音取决于以下coda的拼写。这可能也适用于更大的单位,如最后一个音节。例如,对最后的序列/ʃəs /在上面的例子中喜爱vushus;,一个搜索webCELEX透露,92%的所有单词结束在这个音素序列(91个席位中赢得了99个类型)与喜爱借据;拼,这可以解释观察到的偏爱拼写。未来的研究应该系统地操纵grapheme-phoneme更大的一致性最终音位单位调查的贡献类比新单词拼写。
对预测调制的拼写能力和经验与英语写作系统,目前研究显示拼写能力的影响,参与者更好地执行30-item拼写任务更容易拼写重要小说与喜爱诸多;比名词形容词上下文环境,表明规律逐渐诱导从输入,从而导致更健壮的规则应用程序增加了英语写作系统的经验和专业知识。这一发现与坎普和科比的(2003年(即)观察成人大学教育。,一个large amount of reading and writing) were better at using morphological context in the spelling of novel plural nouns ending in a vowel plus /z/ with the appropriate morphological spelling ‹s›. Treiman et al. (2020年),另一方面,没有发现的调制效应,拼写能力衡量的拼写分测验广泛成就测验(WRAT,威尔金森和罗伯逊2006年),作者认为可能是由于拼写成绩的范围不够大。目前坎普和科比的研究结果表明,对于更好的拼写能力的隐式morpho-graphic拼写规律更巩固,让那些拼写能力更好地利用上下文信息的连接到拼写。一般来说,这些拼写者似乎能够更好地整合不同来源的信息,因为由于自动化,需要更少的资源个体的过程。
有趣的是,一个拼写能力的影响也被报道对morpho-orthographic启动在形态学处理研究。之前的蒙面启动研究表明便利化效果没有形态的质数与他们的目标,但似乎有一个词缀(例如,角落里- - - - - -玉米),参与者“脱”最早喜爱珥;在处理阶段和访问应该阻止(例如,Rastle et al。2004年)。安德鲁斯和罗(2013年发现这个所谓的corner-corn效果为“优秀拼写能力”更强,表明这些参与者的“拼写概要”比“可怜的拼写者”更有可能(错误地)识别字母序列喜爱er;作为词缀。
在连接到上面一点拼写能力,AoA表明拼写行为的主要影响可能取决于接触书写系统的类型。总的来说,参与者接触到英语写作系统后更有可能产生喜爱我们的;拼写(不考虑上下文)。考虑到英语学习者已经收购了一个书写系统(即第一语言)和通常暴露于书面形式的英语从一开始他们的收购过程中,第二语言学习者可能率先巩固拼写词汇条目内表示,注意到morpho-graphic拼写规律,同时,对于母语,拼写表示是后来添加的,需要被映射到语音数据,已经合并了。这种注重拼写的信息也被蒙面启动后期研究学习者所示,对纯粹的所有相关的主要目标有显著促进双等丑闻- - - - - -扫描等,而对不导致本地读者(cf启动。嘿,Clahsen2015年;李等人。2017年)。
其他participant-level因素可能发挥作用的是意识形态和语音解码能力。换句话说,对参与者产生适当的拼写,他们首先必须意识到,这个句子上下文需要一个形容词(和一个名词),然后需要段音位序列/əs /从输入。关于前者,Nunes et al。(1997年,一个,1997 b)发现,参与者在形态认知测试中得分越高的人更有可能是一个更高的舞台上的5级模型word-final t / d /和/ /。因此,未来的研究应该考虑这些其他participant-level因素除了拼写能力。
还会有项目级的应用影响因素morpho-graphic拼写规律:词缀的效率和透明度的问题。第一,参与者可以从输入更容易诱发拼写特点如果词缀问题出现很多不同的基地。例如,尽管喜爱我们的;是一个非常可靠的指标adjectivehood(伯格和Aronoff2017年),词缀不是很高效,与大量的-我们公司形容词有绑定根和/或拉丁词的起源(例如,大胆的,非常滑稽的,巨大的;cf。难2003年:97)。结果,可能更少意识到拼写形容词地位标志,从而需要更长的时间来诱导规律而富有成效的词缀等洛克。
同样,参与者可能会更容易地识别一个后缀和其拼写规律是透明的。不同的后缀可能改变对如何添加语义信息是一致的和透明的。例如,后缀-伊势添加一个不同的意义使住院(“把某人医院”)相比蒸发(把东西变成蒸汽)和的施事的意义呃在名词如贝克或跑步者可能比质量的意义——更加透明我们公司形容词。未来的研究应该系统地比较不同类型的词缀。
结论
目前的研究表明,英语拼写能力意识到隐式morpho-graphic拼写规律和应用到新单词的拼写。然而,他们这样做的程度取决于个体差异:更好的拼字有人无论当暴露于拼写系统启动时,越有可能一个是morpho-graphic拼写规律应用于小说单词拼写。对于这个应用程序,两个条件必须满足:拼写能力需要诱导规律从输入首先,这需要足够的接触书写系统,他们需要集成不同类型的信息在实际拼写事件(例如,所需的词汇范畴句子上下文)。这两个过程应该得到更好的拼写能力因为拼写的自动化过程将导致减少了处理负载,释放资源供其他进程(比如上下文信息的集成)。
笔记
- 1。
在整个论文中,尖括号用来表示字母或字母序列和斜杠用于语音合成。
- 2。
一个额外的参与者进行了测试。然而,她的数据不包括因为事实证明,她没有学习英语(也反映在低LexTALE分数)。
- 3所示。
C =辅音,V =元音。
- 4所示。
可以在网上www.lextale.com。
- 5。
注意使用分类区别有经验的和没有经验的拼写能力而不是产生同样的效果如下报道(-影响的收购(AoA)的时代,这不是母语(即有意义的一次。,该集团的AoA 0)是分开的)。
- 6。
词缀语素变体包含在计数的拼写,因为前面的音素的属性会影响拼写的词缀我们公司。例如,序列/ʃəs几乎总是拼写与喜爱欠条;(例如,珍贵的,亲切的,雄心勃勃的)或有时喜爱eous;(4例CELEX:例如,曲线美,草本),只有两个例外CELEX(即。的名字孔子和毛里求斯)。
- 7所示。
注意,这个数包括语素变体喜爱欠条;和喜爱eous;。
- 8。
- 9。
注意与LexTALE得分和AoA不在模型中,因为他们并没有显著改善模型。
- 10。
注:相同的模式的结果出现在其他形容词的词缀(即。、喜爱;少、喜爱伊什;)包含在因变量。
引用
Abrahantes, j . C。,& Aerts, M. (2012). A solution to separation for clustered binary data.统计建模,12(1)3-27。
安德鲁斯,S。,& Lo, S. (2013). Is morphological priming stronger for transparent than opaque words? It depends on individual differences in spelling and vocabulary.杂志的记忆和语言,68年,279 - 296。
Aronoff, M。Berg, K。,& Heyer, V. (2016). Some implications of English spelling for morphological processing.心理词汇,11,164 - 185。
Audacity团队(2017)。Audacity (R):免费的音频编辑和记录器(计算机应用)。2.1.3版本检索2017年5月22日https://audacityteam.org/。
Baayen, r . H。,Piepenbrock, R., & Gulikers, L. (1995). The CELEX lexical database (Release 2, English version 2.5. [CD-ROM]. Philadelphia: Linguistic Data Consortium, University of Pennsylvania.
Balota, d . A。废话,m . J。,Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., Neely, J. H., Nelson, D. L., Simpson, G. B., & Treiman, R. (2007). The English lexicon project.行为研究方法,39,445 - 459。
巴里,C。,& Seymour, P. H. K. (1988). Lexical priming and sound-to-spelling contingence affects in nonword spelling.季度《实验心理学》杂志上,40,有些人。
贝茨,D。,米一个echler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4.杂志的统计软件,67年(1)1。
Berg, K。,& Aronoff, M. (2017). Self-organization in the spelling of English suffixes: The emergence of culture out of anarchy.语言,93年(1),37 - 64。
Berg, K。,Buchmann, F., Dybiec, K., & Fuhrhop, N. (2014). Morphological spellings in English.书面语言和文学,14,282 - 307。
伯特,j·S。,& Tate, H. (2002). Does a reading lexicon provide orthographic representations for spelling?杂志的记忆和语言,46,518 - 543。
卡尼,大肠(1994)。英语拼写的调查。纽约:劳特利奇。
钟,Y。,Rabe-Hesketh, S., Dorie, V., Gelman, A., & Liu, J. (2013). A nondegenerate penalized likelihood estimator for variance parameters in multilevel models.心理测量学,78年(4),685 - 709。
Delattre, M。小笠原,P。,& Barry, C. (2006). Written spelling to dictation: Sound-to-spelling regularity affects both writing latencies and durations.实验心理学杂志》上。学习、记忆和认知,32,1330 - 1340。
弗斯,d . (1993)。减少偏见的最大似然估计。生物统计学,80年,27-38。
福斯特,k。,& Forster, J. C. (2003). DMDX: A Windows display program with millisecond accuracy.行为研究方法、仪器和电脑,35,116 - 124。
>。,Jakulin, A., Pittau, M. G., & Su, T. S. (2008). A weakly informative default prior distribution for logistic and other regression models.应用统计年鉴,2,1360 - 1383。
Gontijo, p . f . D。Gontijo,我。,& Shillcock, R. (2003). Grapheme-phoneme probabilities in British English.行为研究方法、仪器和电脑,35,136 - 157。
嘿,V。,& Clahsen, H. (2015). Late bilinguals see a扫描在扫描仪而在丑闻:从形态解剖正式重叠处理的启动派生的名词。双语:语言和认知,18(3),543 - 550。
坎普,N。,& Bryant, P. (2003). Do beez buzz? Rule-based and frequency-based knowledge in learning to spell plural -s.儿童发展,74年,63 - 74。
凯斯勒,B。,& Treiman, R. (2001). Relationships between sounds and letters in English monosyllables.杂志的记忆和语言,44,592 - 617。
Lemhofer, K。,& Broersma, M. (2012). Introducing LexTALE: A quick and valid Lexical Test for Advanced Learners of English.行为研究方法,44,325 - 343。
李,J。,Taft, M., & Xu, J. (2017). The processing of English derived words by Chinese-English bilinguals.语言学习,64年(4),858 - 884。
玛丽安,V。,Bartolotti, J., Chabal, S., & Shook, A. (2012). CLEARPOND: Cross-Linguistic Easy-Access Resource for Phonological and Orthographic Neighborhood Densities.《公共科学图书馆•综合》,7(8),e43230。https://doi.org/10.1371/journal.pone.0043230。
Nagy, w·E。,& Anderson, R. (1984). The number of words in printed school English.阅读研究季刊,19,304 - 330。
Nunes, T。,Bryant, P., & Bindman, M. (1997a). Learning to spell regular and irregular verbs.阅读和写作,9,427 - 449。
Nunes, T。,Bryant, P., & Bindman, M. (1997b). Morphological spelling strategies: Developmental stages and processes.发展心理学,33,637 - 649。
难陀,即(2003)。英语构词。剑桥:剑桥大学出版社。
R核心团队(2017)。接待员:统计计算的语言和环境。维也纳:R统计计算的基础。从检索www.Rproject.org。
Rastle, K。,Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morphoorthographic segmentation in visual word recognition.心理环境通报与评论,11,1090 - 1098。
Treiman, R。,Wolter, S., & Kessler, B. (2020). How sensitive are adults to the role of morphology in spelling?形态。https://doi.org/10.1007/s11525 - 020 - 09356 - 4。
Ulicheva,。哈维,H。,Aronoff, M。,& Rastle, K. (2020). Skilled readers’ sensitivity to meaningful regularities in English writing.认知,195年,103810年。
威尔金森,g S。,& Robertson, G. J. (2006).广泛成就测验(WRAT4)。Lutz:心理评估资源。
确认
我想谢谢马克Aronoff和克里斯蒂安·伯格的合作这个项目起源于以及编辑这个特殊问题,丽贝卡Treiman和两个匿名评论者对他们有帮助的反馈早期版本的手稿,Kenton巴恩斯的记录刺激,研讨会的与会者“书面英语”的形态和布伦瑞克大学的语言学团队反馈,参与者对他们的时间,Berit Gende,蒂娜马提亚利亚Wildner协助数据收集和/或编码,最后但并非最不重要,若昂Verissimo建议分析。
资金
开放获取资金启用并由Projekt交易。
作者信息
从属关系
相应的作者
额外的信息
出版商的注意
beplay登入施普林格自然保持中立在发表关于司法主权地图和所属机构。
附录
附录
项目测量拼写能力(选自伯特和泰特(2002年)实验3)
共犯;粘着的;加剧;湮灭;先行词;评估员;同化;口语;调解;消化; diligent; gullible; innuendo; insatiable; insolent; invincible; lingerie; oblivion; omniscient; parachute; pinnacle; plagiarism; recurrence; repetitive; rigidity; subtlety; succinct; tranquil; vehicular; vigilant
权利和权限
开放获取本文是基于知识共享署名4.0国际许可,允许使用、共享、适应、分布和繁殖在任何媒介或格式,只要你给予适当的信贷原始作者(年代)和来源,提供一个链接到创作共用许可证,并指出如果变化。本文中的图片或其他第三方材料都包含在本文的创作共用许可证,除非另有说明在一个信用额度的材料。如果材料不包括在本文的创作共用许可证和用途是不允许按法定规定或超过允许的使用,您将需要获得直接从版权所有者的许可。查看本许可证的副本,访问http://creativecommons.org/licenses/by/4.0/。
关于这篇文章

引用这篇文章
嘿,诉低于表面:隐式morpho-graphic规律的应用新单词拼写。形态31日,243 - 260 (2021)。https://doi.org/10.1007/s11525 - 020 - 09370 - 6
收到了:
接受:
发表:
发行日期:
关键字
- Morpho-graphic拼写
- 新单词拼写
- 派生形态学
- 心理语言学
- 拼写的能力